The Challenge: MIMIC 데이터의 복잡성
분당서울대병원 주관 대회에 참가하여, 전 세계적으로 가장 유명한 중환자실(ICU) 오픈 데이터셋인 MIMIC을 활용했습니다. 목표는 환자의 데이터를 분석해 급성신손상(AKI)을 조기에 탐지하는 것이었습니다.
가장 큰 난관은 데이터가 수십 개의 테이블로 파편화되어 있어 어떤 데이터가 유효한지 판단하기 어려웠고, '중증환자(ICU)' 데이터와 '외래진료' 데이터가 분리되어 있어 환자의 상태를 연속적으로 파악하기 힘들다는 점이었습니다.
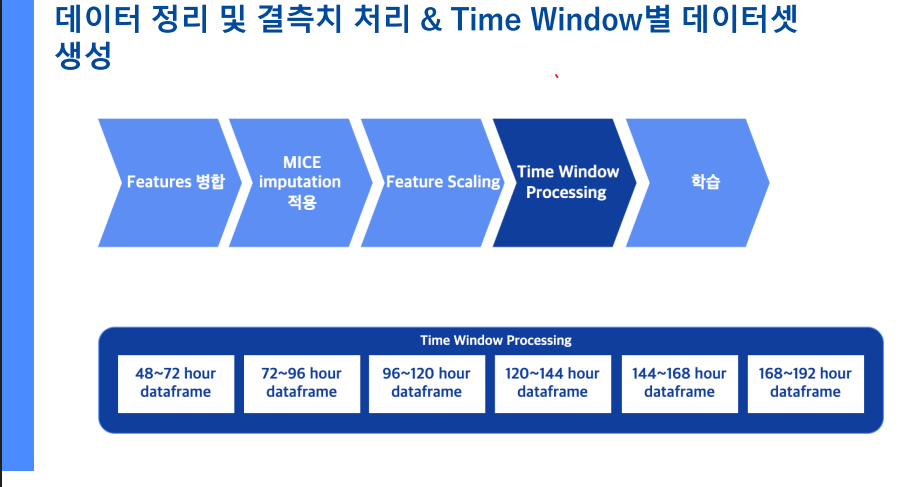
▲ 슬라이딩 윈도우 분리 및 전처리과정
My Key Contribution: 데이터 엔지니어링
저는 팀에서 원시 데이터(Raw Data)를 모델이 학습 가능한 형태로 가공하는 핵심적인 데이터 엔지니어링 역할을 수행했습니다.
-
1. 핵심 지표(Creatinine) 발굴 및 데이터 통합
수많은 의료 지표 중 신장 기능과 가장 상관관계가 높은 것이 크레아틴(Creatinine) 수치임을 도메인 조사를 통해 확인했습니다. 이를 기준으로 각 환자의 활력 징후(Vital Signs)와 검사 결과 데이터를 하나의 통합 테이블로 병합(Merge)했습니다.
-
2. 시계열 데이터 확장 (ICU + 외래 데이터)
중증환자 데이터만으로는 장기적인 추이를 보기 어렵다는 한계가 있었습니다. 저는 중증환자이면서 동시에 외래 진료 기록이 있는 교집합 환자를 찾아내어, 외래 데이터를 시계열 앞단에 붙여 데이터의 타임라인(개월 수)을 확장시키는 작업을 주도했습니다. 이를 통해 모델이 환자의 장기적인 건강 변화 추이를 학습할 수 있게 만들었습니다.
Modeling & Results
-
슬라이딩 윈도우 & 앙상블
환자마다 입원 기간이 다른 문제를 해결하기 위해 슬라이딩 윈도우(Sliding Window) 기법으로 데이터를 일정 구간씩 잘라 학습셋을 구성했습니다. 각 윈도우별로 학습된 개별 모델들을 앙상블하여 예측의 안정성을 높였습니다.
-
불균형 해소 및 성능 달성
정상 환자가 압도적으로 많은 의료 데이터 특성상 발생하는 불균형 문제는 SMOTE 기법을 통한 데이터 증강으로 완화했습니다. 최종적으로 약 90%의 정확도를 달성했으며, 학습/테스트 데이터를 철저히 분리하여 과적합 없이 일반화된 성능을 입증했습니다.